Two years ago when Google switched to Hanyu Pinyin in its maps of Taiwan, it did a poor job … despite the welcome use of tone marks.
Here are some of the problems I noted at the time:
- The Hanyu Pinyin is given as Bro Ken Syl La Bles. (Terrible! Also, this is a new style for Google Maps. Street names in Tongyong were styled properly: e.g., Minsheng, not Min Sheng.)
- The names of MRT stations remain incorrectly presented. For example, what is referred to in all MRT stations and on all MRT maps as “NTU Hospital” is instead referred to in broken Pinyin as “Tái Dà Yī Yuàn” (in proper Pinyin this would be Tái-Dà Yīyuàn); and “Xindian City Hall” (or “Office” — bleah) is marked as Xīn Diàn Shì Gōng Suǒ (in proper Pinyin: “Xīndiàn Shìgōngsuǒ” or perhaps “Xīndiàn Shì Gōngsuǒ“). Most but not all MRT stations were already this incorrect way (in Hanyu Pinyin rather than Tongyong) in Google Maps.
- Errors in romanization point to sloppy conversions. For example, an MRT station in Banqiao is labeled Xīn Bù rather than as Xīnpǔ. (埔 is one of those many Chinese characters with multiple Mandarin pronunciations.)
- Tongyong Pinyin is still used in the names of most cities and townships (e.g., Banciao, not Banqiao).
I’m pleased to report that Google Maps has recently made substantial improvements.
First, and of fundamental importance, word parsing has finally been implemented for the most part. No more Bro Ken Syl La Bles. Hallelujah!
Here’s what this section of a map of Tainan looked like two years ago:
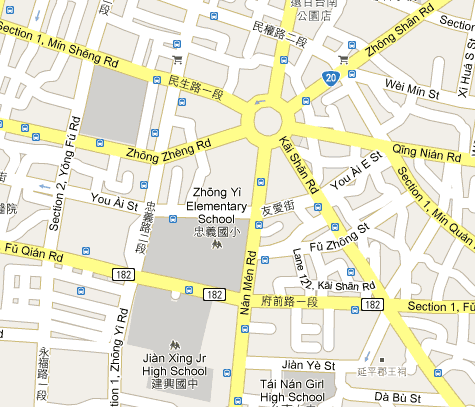
And here’s how it is now:

Oddly, “Jiànxīng Jr High School” has been changed to “Tainan Municipal Chien-Shing Jr High School Library” — which is wordy, misleading (library?), and in bastardized Wade-Giles (misspelled bastardized Wade-Giles, at that). And “Girl High School” still hasn’t been corrected to “Girls’ High School”. (We’ll also see that problem in the maps for Taipei.)
But for the most part things are much better, including — at last! — a correct apostrophe: Yǒu’ài St.
As these examples from Taipei show, the apostrophe isn’t just a one-off. Someone finally got this right.
Rén’ài, not Renai.

Cháng’ān, not Changan.

Well, for the most part right. Here we have the correct Dà’ān (and correct Ruì’ān) but also the incorrect Daan and Ta-An. But at least the street names are correct.

Second, MRT station names have been fixed … mostly. Most all MRT station names are now in the mixture of romanization and English that Taipei uses, with Google Maps also unfortunately following even the incorrect ones. A lot of this was fixed long ago. The stops along the relatively new Luzhou line, however, are all written wrong, as one long string of Pinyin.
To match the style used for other stations, this should be MRT Songjiang Nanjing, not Jieyunsongjiangnanjing.

Third, misreadings of poyinzi (pòyīnzì/破音字) have largely been corrected.
Chéngdū, not Chéng Dōu.

Like I said: have largely been corrected. Here we have the correct Chéngdū and Chóngqìng (rather than the previous maps’ Chéng Dōu and Zhòng Qìng) but also the incorrect Houbu instead of the correct Houpu.

But at least the major ones are correct.
Unfortunately, the fourth point I raised two years ago (Tongyong Pinyin instead of Hanyu Pinyin at the district and city levels) has still not been addressed. So Google is still providing Tongyong Pinyin rather than the official Hanyu Pinyin at some levels. Most of the names in this map, for example, are distinctly in Tongyong Pinyin (e.g., Lujhou, Sinjhuang, and Banciao, rather than Luzhou, Xinzhuang, and Banqiao).

Google did go in and change the labels on some places from city to district when Taiwan revised their names; but, oddly enough, the company didn’t fix the romanization at the same time. But with any luck we won’t have to wait so long before Google finally takes care of that too.
Or perhaps we’ll have a new president who will revive Tongyong Pinyin and Google will throw out all its good work.



















