When Google Translate‘s Pinyin converter was first released about a year and a half ago, it sucked. Wow, did it ever suck. Since then, however, Google has instituted some changes. So it seems about time this was reexamined.
Fortunately, Google’s Pinyin converter is now much better than before.
Here’s the sort of FUBAR romanization — it certainly doesn’t deserve to be called Hanyu Pinyin — Google used to produce:
tán zhōng guó de“yǔ“hé” wén” de wèn tí, wǒ jué de zuì hǎo néng xiān liǎo jiè yī xià zài zhōng guó tōng yòng de yǔ yán。… rú guǒ nǐ shǐ yòng zhōng guó de gòng tóng yǔ yán pǔ tōng huà, nǐ liǎo jiě zhè ge yǔ yán de yǔ fǎ(bǐ rú“de, de, de“ hé“le” de bù tóng yòng fǎ) ma?zhī dào zhè ge yǔ yán de jī běn yīn jié(bù bāo kuò shēng diào) zhǐ yǒu408gè ma?
Now the same passage will look like this:
Tán zhōngguó de “yǔ” hé “wén” de wèntí, wǒ juéde zuì hǎo néng xiān liǎo jiè yīxià zài zhōngguó tōngyòng de yǔyán…. Rúguǒ nǐ shǐyòng zhōngguó de gòngtóng yǔyán pǔtōnghuà, nǐ liǎojiě zhège yǔyán de yǔfǎ (bǐrú “de, de, de “hé “le” de bùtóng yòngfǎ) ma? Zhīdào zhège yǔyán de jīběn yīnjié (bù bāokuò shēngdiào) zhǐyǒu 408 gè ma?
At last! Capitalization at the beginning of a sentence and word parsing! But — you knew there was going to be a but, didn’t you? — Google’s Pinyin converter falls significantly short because it still fails completely in two fundamental areas: capitalization of proper nouns and proper use of the apostrophe.
1. Proper Nouns
Google’s Pinyin converter fails to follow the basic point of capitalizing proper nouns. For example, here are some well-known place names. I have prefixed the names with “在” because Google automatically capitalizes the first word in a line; so to see how it handles capitalization of place names something other than the name must go first.
![screenshot showing what happens if the following is entered into Google Translate: '在西安, 在长安, 在重庆, 在北京'. That leads to the following in Google Translate: 'in Xi'an, in Chang [sic], in Chongqing, in Beijing'. But the romanization line reads 'Zai xian, Zai changan, Zai chongqing, Zai beijing'](https://pinyin.info/news/news_photos/2011/06/google_translate_xian2.gif "google_translate_xi'an2")
Google Translate gets these right, other than the odd truncation of Chang’an. But the Pinyin converter (see the gray text at the bottom of the image above) fails to capitalize these, even though it correctly parses them as units and thus must “know” their meanings.
The same thing happens with personal names.
Input this:
是馬英九
是毛泽东
是陳水扁
Google Translate provides this:
Is Ma Ying-jeou
Mao Zedong
Chen Shui-bian
Those are correct, if the missing Iss are discounted.
But the Pinyin appears as “Shì mǎyīngjiǔ Shì máozédōng Shì chénshuǐbiǎn“. So even though the software understands that these names are units, the capitalization and word parsing are still wrong and they are still not rendered as they should be in Pinyin: “Mǎ Yīngjiǔ,” “Máo Zédōng,” “Chén Shuǐbiǎn.”
There is nothing obscure about capitalizing proper nouns. How did this get missed?
2. Apostrophes
The cases of Xi’an and Chang’an above already demonstrate apostrophe omission. Let’s try a few more tests, including some words that are not proper nouns.
Input this:
阿爾巴尼亞
然而
仁愛
蓮藕
The Pinyin is rendered as “Āěrbāníyǎ Ránér Rénài Liánǒu” rather than the correct forms of Ā’ěrbāníyǎ, rán’ér, rén’ài, and lián’ǒu.
As always I want to stress that, whatever you might have heard elsewhere, apostrophes are not optional. But the rules for their use are easy — so easy that I suspect a fairly simple computer script could fix this problem quickly and simply. (Only about 2 percent of Mandarin words, as written in Hanyu Pinyin, have apostrophes.)
As is the case with the mistakes with proper nouns, these apostrophe errors are all the more puzzling because Google Translate does not appear to share them. Fortunately, these problems should not be particularly difficult to fix, especially if the Pinyin converter can make better use of Google Translate’s database.
Although Google’s failures to implement capitalization of proper nouns and apostrophe use are significant problems, they could likely be corrected quickly and easily. (I strongly suspect this would take considerably less time than it has taken for me to write this post.) The result would be a vastly improved converter. So I am hopeful that Google will work on this soon.
3. Additional work
Once Google gets those basics fixed, it should focus on the simple matter of correcting spacing before and after some quotations (which would surely take just a few minutes to take care of) and any other such spacing errors, and fixing its word parsing related to numbers (which is a bit more complicated, though the basics are easy: everything from 1 to 100 is written solid).
Next would come something requiring a bit more care: the proper handling of Mandarin’s three tense-marking particles: zhe, guo, and le.
And Google should attach the pluralizing suffix -men to the word it modifies rather than leaving it separate (e.g., háizimen, not háizi men).
Then, with all of those taken care of, Google would have a pretty good Pinyin converter that I would be happy to praise. Of course even then it could still use other improvements; but those would most likely deal more with particulars than the fundamentals of how Pinyin is meant to be written.
A separate post, to be written soon, will compare the performance of several Pinyin converters (including Google’s). Stay tuned.





















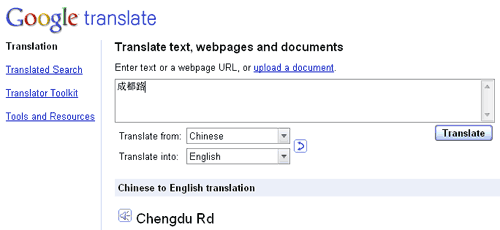
![screenshot from Google Maps of 'Cheng Dou [sic] Rd', near Taipei's Ximending](https://pinyin.info/news/news_photos/2009/11/cheng_dou_road.gif)
{kind=link}