Recently someone wrote me with a problem. She had a book-length manuscript, most of which was in English. It also had some Chinese characters interspersed throughout the text. She needed to make some alterations to just the parts in Chinese characters and was hoping to avoid going through the entire Microsoft Word document line by line and changing the Chinese characters phrase by phrase. That could have taken hours or even days.
Fortunately, there’s a much easier and much faster way. So here’s how to search for Chinese characters inside a Microsoft Word document.
First, the simplest and easiest way. Copy the following line:
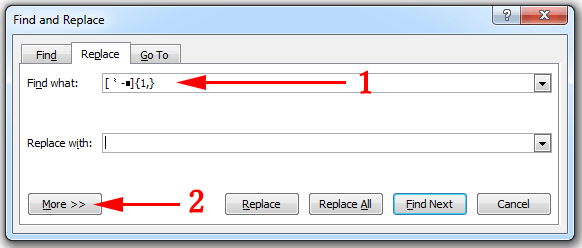
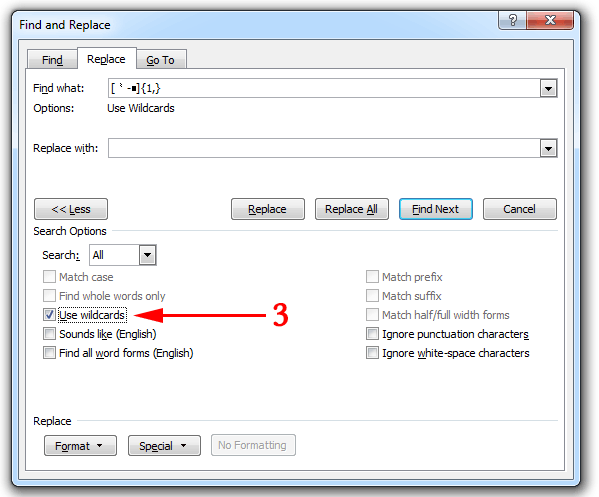
[⺀-■]{1,}
In Microsoft Word, use Ctrl+H to bring up the Find and Replace box.
- Paste the text you just copied in the
Find what box.
- Click on the
More >> button to reveal additional options.
- Select
Use wildcards.
Then Find away. That’s all there is to it. You can alter all the Chinese characters you find at the same time if you so desire.
Pro tip: If you want to change something about the Chinese characters, you might be better off in the long run making a new Word style and changing all the relevant characters to that style and then adjusting the style to meet your needs. Use Replace → Format → Style....
———–
Now comes a longer explanation, which you can safely ignore if the above worked fine for you.
But in case the special code above didn’t work for you or if you’d like to understand this a little better, here’s some more information on how to enter [⺀-■]{1,} yourself and why it works.
Basically, what you’re searching for is a range of characters, such as everything from A to Z. But in this case you’re going to be looking for everything from the start to the finish of Unicode’s set of graphs related to Chinese characters. Word calls this a wildcard search. Others refer to the use of wildcards as “regular expressions,” or “regex” for short.
Searches for ranges go in square brackets, with a hyphen between the first character and the last one, e.g. [A-Z].
The part at the end, {1,}, just tells Microsoft Word to look for one or more of the previous expression, so it will locate entire sections in Chinese characters, not just one character at a time. That will save you a lot of time and trouble.
OK, to get those special characters in a Word document, use
- Insert
- Symbol
- More Symbols
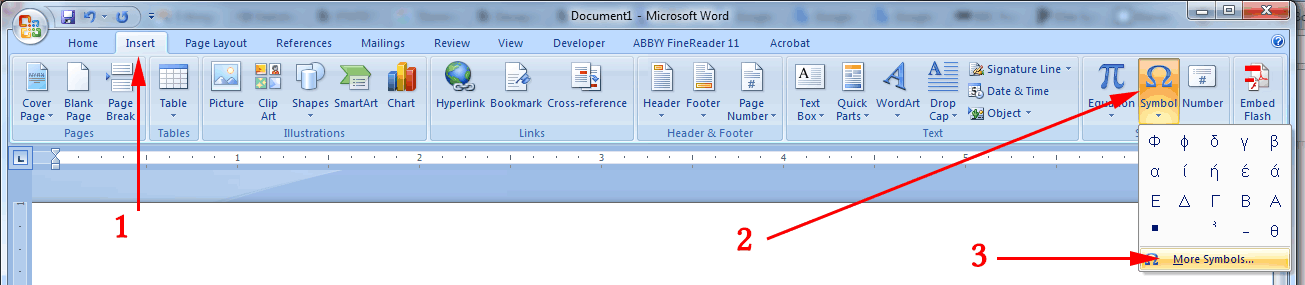
Next,
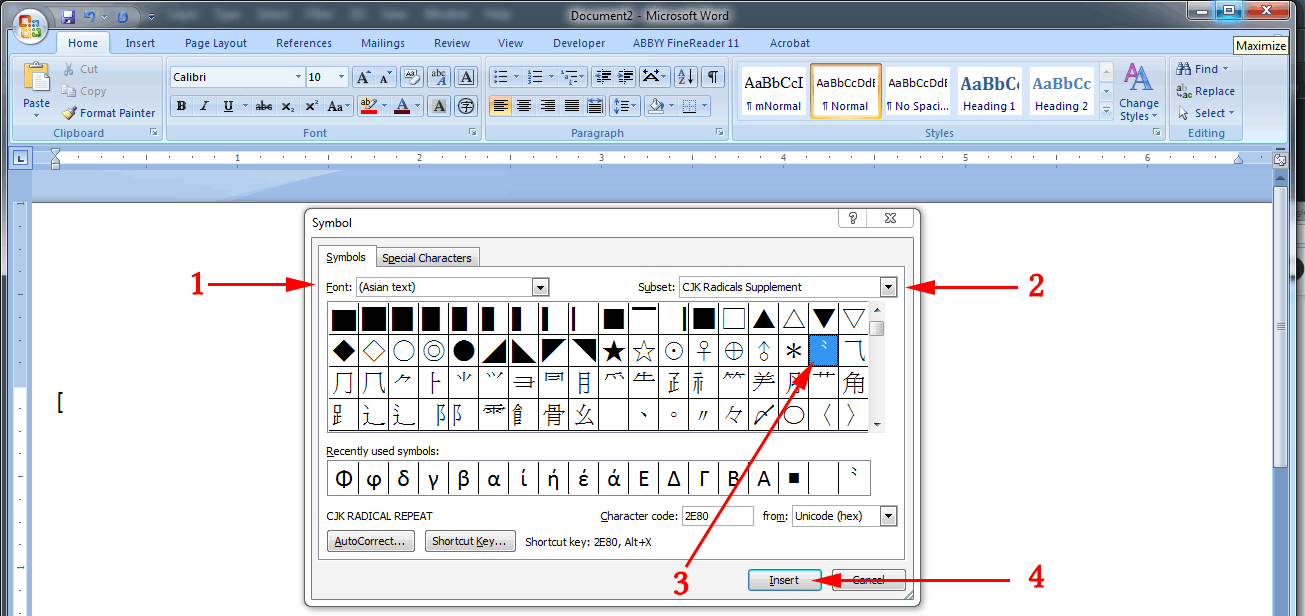
- Under
Font, select (Asian text).
- Under
Subset, scroll down until you can select the CJK Radicals Supplement.
- Word should have already selected ⺀ (CJK Radical Repeat) for you. If not, you can click on it.
- Click the
Insert button.
If needed, repeat Insert → Symbol → More Symbols.
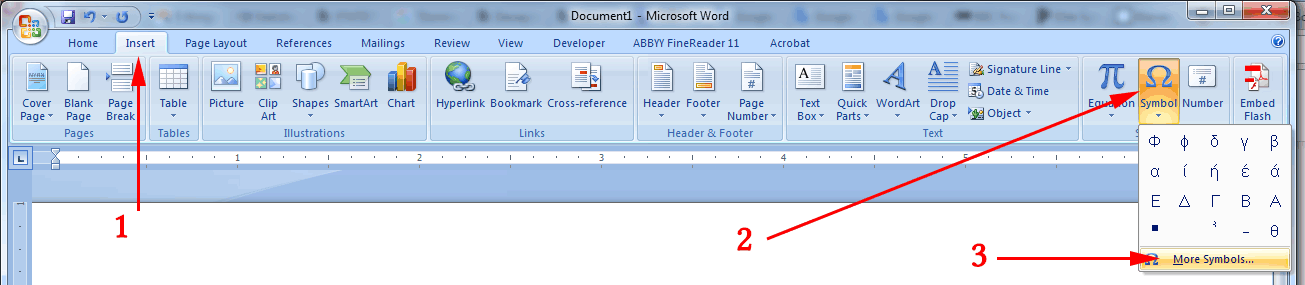
This time, with Font, still set at (Asian text):
- Under
Subset, scroll all the way down until you can select the Halfwidth and Fullwidth Forms.
- Scroll all the way down the selection of glyphs and select the very last one.
- Click the
Insert button.
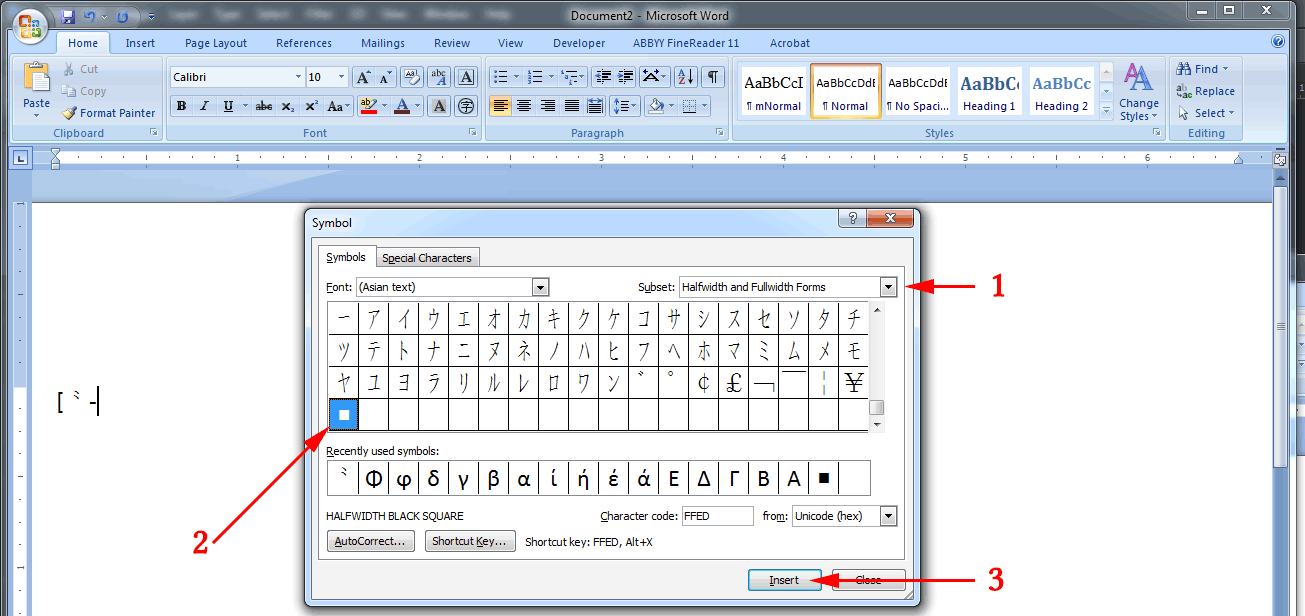
On my system at the moment that final character is a “halfwidth black square.” But as Unicode — and fonts — expand, the final character may be something else. Just use whatever is last and you should be fine. Just be sure to type in the square brackets, the hyphen, and the {1,} to complete the expression:
[⺀-■]{1,}
In case anyone’s wondering, no, you can’t just enter Unicode code numbers, because searches for those (u^ +number) won’t work when “Use wildcards” is on. So you have to enter the characters themselves.
This method can be easily adapted to suit searches for Greek letters, Cyrillic, etc.
I hope you find it useful.