
Recently someone wrote me with a problem. She had a book-length manuscript, most of which was in English. It also had some Chinese characters interspersed throughout the text. She needed to make some alterations to just the parts in Chinese characters and was hoping to avoid going through the entire Microsoft Word document line by line and changing the Chinese characters phrase by phrase. That could have taken hours or even days.
Fortunately, there’s a much easier and much faster way. So here’s how to search for Chinese characters inside a Microsoft Word document.
First, the simplest and easiest way. Copy the following line:
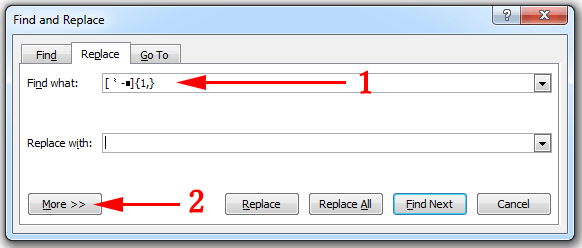
[⺀-■]{1,}
In Microsoft Word, use Ctrl+H to bring up the Find and Replace box.
- Paste the text you just copied in the
Find whatbox. - Click on the
More >>button to reveal additional options. - Select
Use wildcards.
Then Find away. That’s all there is to it. You can alter all the Chinese characters you find at the same time if you so desire.
Pro tip: If you want to change something about the Chinese characters, you might be better off in the long run making a new Word style and changing all the relevant characters to that style and then adjusting the style to meet your needs. Use Replace → Format → Style....
———–
Now comes a longer explanation, which you can safely ignore if the above worked fine for you.
But in case the special code above didn’t work for you or if you’d like to understand this a little better, here’s some more information on how to enter [⺀-■]{1,} yourself and why it works.
Basically, what you’re searching for is a range of characters, such as everything from A to Z. But in this case you’re going to be looking for everything from the start to the finish of Unicode’s set of graphs related to Chinese characters. Word calls this a wildcard search. Others refer to the use of wildcards as “regular expressions,” or “regex” for short.
Searches for ranges go in square brackets, with a hyphen between the first character and the last one, e.g. [A-Z].
The part at the end, {1,}, just tells Microsoft Word to look for one or more of the previous expression, so it will locate entire sections in Chinese characters, not just one character at a time. That will save you a lot of time and trouble.
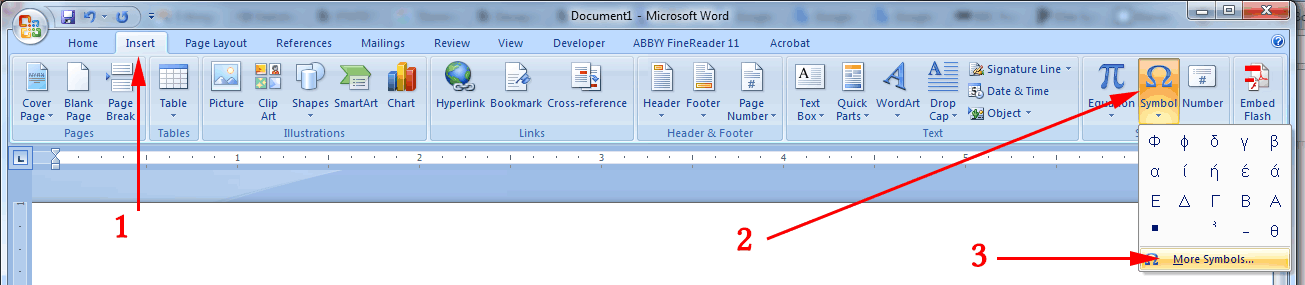
OK, to get those special characters in a Word document, use
- Insert
- Symbol
- More Symbols
Next,
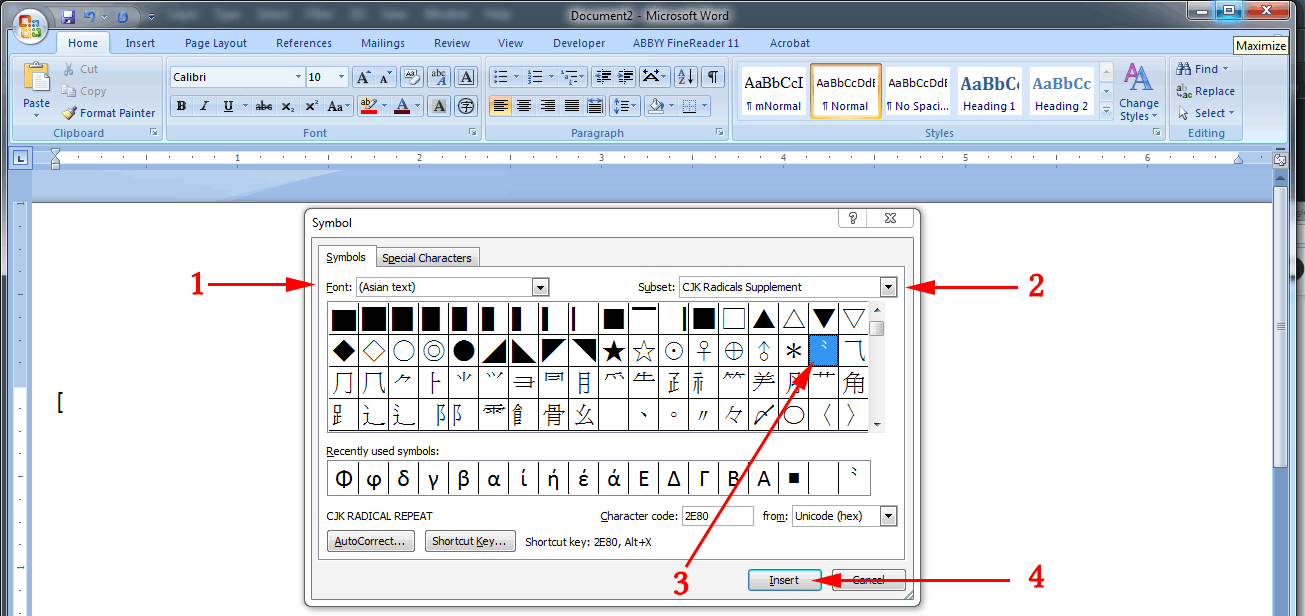
- Under
Font, select(Asian text). - Under
Subset, scroll down until you can select theCJK Radicals Supplement. - Word should have already selected ⺀ (CJK Radical Repeat) for you. If not, you can click on it.
- Click the
Insertbutton.
If needed, repeat Insert → Symbol → More Symbols.
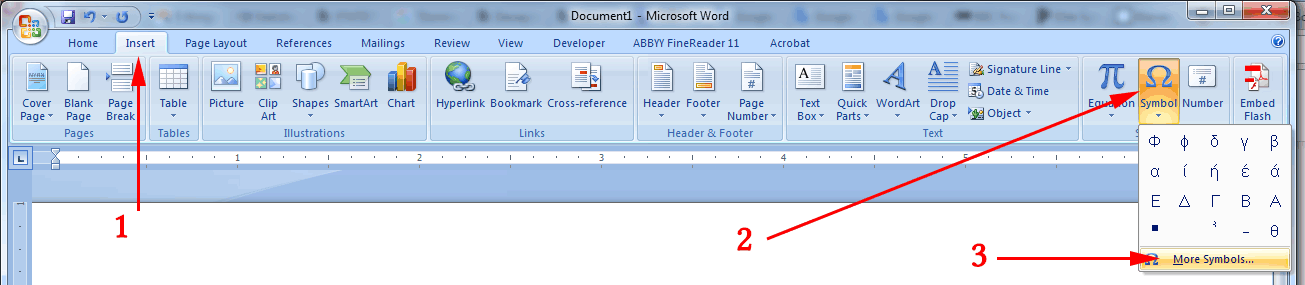
This time, with Font, still set at (Asian text):
- Under
Subset, scroll all the way down until you can select theHalfwidth and Fullwidth Forms. - Scroll all the way down the selection of glyphs and select the very last one.
- Click the
Insertbutton.
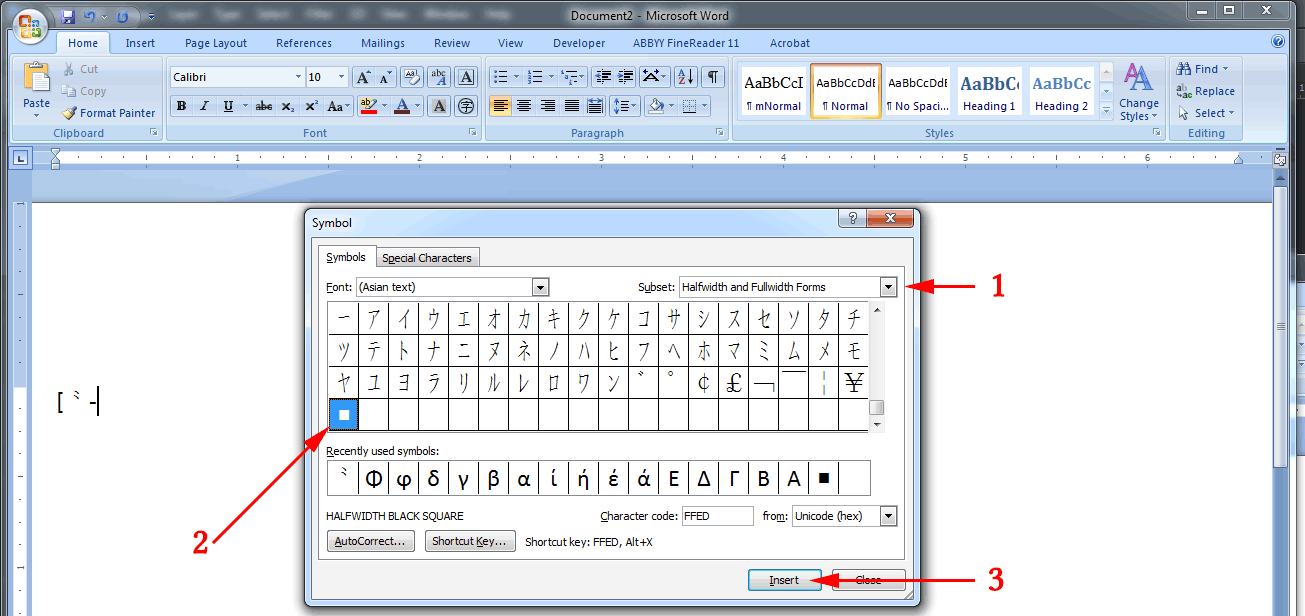
On my system at the moment that final character is a “halfwidth black square.” But as Unicode — and fonts — expand, the final character may be something else. Just use whatever is last and you should be fine. Just be sure to type in the square brackets, the hyphen, and the {1,} to complete the expression:
[⺀-■]{1,}
In case anyone’s wondering, no, you can’t just enter Unicode code numbers, because searches for those (u^ +number) won’t work when “Use wildcards” is on. So you have to enter the characters themselves.
This method can be easily adapted to suit searches for Greek letters, Cyrillic, etc.
I hope you find it useful.
Thank you! I used it to delete chinese characters from a large doc.
Wow, this was crazy useful. Thank you for answering this question so clearly. I had this exact problem and your advice solved it perfectly.
If I could, I would nominate you for Knighthood. Your simple explanation broke a frustrating logjam in my working relationship with Word. The irony of your solution is that I’m familiar with regular expressions (even have a book on the subject), but it never occurred to me to use ranges as a wildcard. Your idea will be forever seared into my consciousness. And, not least, get my work done without loss of sanity. Thank you.
Awesome! Word keeps screwing with the standard formatting of Chinese characters in my thesis. Now I can select them all at once and format them in a font that works better. Thank you so much!
Wow this was great. I was dealing with a client’s poorly formatted doc and needed a quick way to change all the Asian characters from one font to another without touching the English characters. This was a lifesaver and this makes me more curious about the robustness of more advanced find/replace in all kinds of contexts.
Thanks for the post. But I am using Word 2003, which I prefer to later versions.
But when I open the “find” etc menu, I can’t paste chinese text ino the find what box. Click but nothing shows.
Is there a solution?
Thanks
In Word 2010, how to automatically insert a space between each Chinese words using Find & Replace?
I’d like to seperate words by a space for further processing purpose.
Thank you.
Word already has something like that built in, at least in terms of appearance. Select the text, then right click. Choose
Paragraph –> Asian Typography –> Automatically adjust space between Asian and Latin text
Alternately, if you want a real space, run a wildcard search for this:
([!⺀-■])([⺀-■]{1,})([!⺀-■])
and replace with this:
\1 \2 \3
Basically, that looks for anything that’s not a Chinese character that is immediately followed by one or more Chinese characters … and then followed by anything that’s not a Chinese character. Then it inserts one space between each of those points.
Sorry, I see that’s perhaps not what you want.
If you want word (ci/詞) spacing in text in Chinese characters (which is something I hope more people will adopt), MS Word 2010 isn’t up to the task. Instead, you should use something like Wenlin or Chinese Key.
But if you want a space between each Chinese character (zi/字), which is something I hope you don’t want, then you could do a wildcard search for this:
([⺀-■])
and replace with this:
\1
(NB: There should be a space before the slash and after the 1.)
Then replace all the double spaces with single spaces.
But perhaps better than having a space between every character would be to have the appearance of a space between every character. Do this by first selecting the text. Then right click. Choose
Font –> Character spacing –> Spacing –> Expanded.
And then set “by” to whatever size pleases you.
Great tips!
These inputs [⺀-■]{1,} and ([!⺀-■])([⺀-■]{1,})([!⺀-■]) look like junk characters to me. I did a try and they worked well! How did you guys find out the magic that these “incantation” can play in the MS WORD? As a English-Chinese translator I myself had considered myself a half-expert with MS WORD but was never aware of this feature. Sometimes when I need to remove unnecessary Chinese characters from a big document with mixed bilingual translation text, I had to do that manually and as you can image, that would be very time consuming.
Thanks for sharing. This is another little tool that helps me enhance my efficiency.
Incredible article, you did a very good job and saved me from hundreds of hours lost in cancelling the Chinese text.
Just to share my experience with your advice using Office 365 with Word 2016, the string [⺀-■]{1,} didn’t work (Warning box saying something went wrong) BUT this [⺀-■] works perfectly!
Thank you very much.
All the best.
Thanks for yr excellent guide. But here’s an issue (problem) you don’t address.
Supposing I want to search for a Chinese name or word string across a whole DIRECTORY folder such as comes up in a windows directory search (the folder icon)?
Thanks in advance
Thanks for yr excellent guide. But here’s an issue (problem) you don’t address.
Supposing I want to search for a Chinese name or word string across a whole DIRECTORY folder such as comes up in a windows directory search (the folder icon)?
Thanks in advance
@James Polacheck, see my new post on “How to find Windows files that contain Chinese characters.”
really appreciate , I liked this one too
Thanks! You’re the bomb!
Thanks for this helpful and comprehensive guide!
its been extremely useful!
Many thanks for this hack! It would have saved me lots of time…
Though, I have a problem: This way to search for characters also finds all “umlaut” (e.g. ü) and special characters as “:”. Is there any workaround for that.
Many thanks in advance!
Patricia
@Patricia,
My method won’t flag regular characters such as ü and :.
I think what is happening is that your text has some “full-width” versions of some characters (i.e., those that are commonly used in texts predominantly in Chinese characters).
Compare, for example, : (full-width colon, which is what you give above) and : (regular colon). The former will be found by my method, whereas the latter won’t.
So I think the method is doing what it should. But if you don’t want to have full-width versions show up on searches, you could try ending the search phrase with 舘, like this:
[⺀-舘]{1,}
But that runs the risk that some obscure Chinese characters won’t be flagged in your searches.
I hope this helps.
@Pinyin Info
So many thanks for your swift response and the alternative search phrase!
I have tried [?-?]{1,} but apparently it shows no results, or it ends up in errors :(
I have checked the letters/characters for the full-width colon and regular colon issue, but it hasn’t shown any effect, when I edited it once more.
I will try my best to find a solution to share here soon.
Is there any way to find Chinese numbers alone from a Chinese word document?
For example, I would like to find any Chinese number
三 which represents 3. OK
三月 which represents March. OK
三角形 which represents triangle. NOT OK.
I want to find any chinese number if it is in number form or with date/month/year. but not as part of chinese word.
I have 50 pages of Word document. Is it possible to delete all chinese characters in one go?
@Secaf: Yes. It’s that easy.
You may wish to be careful about that, though, as some documents (esp. those written mainly in Mandarin rather than a language whose standard script is in an alphabet) do not have spaces between Chinese characters and alphabetic text. Thus, given the text “I愛Hanyu Pinyin” (as opposed to “”I 愛 Hanyu Pinyin”), this method will return “IHanyu Pinyin”. So in the “Replace” box you may wish to insert some unique string (e.g., ” ##### “) so, if needed, you can easily find places that might need tweaking.
Thanks so much for this information. Is there a way to search for all Chinese Characters at 12pt font? I want to select only the 12pt font characters so I can bump them up to 14pt using a character style.
@R-dog:
Yes, that’s easy.
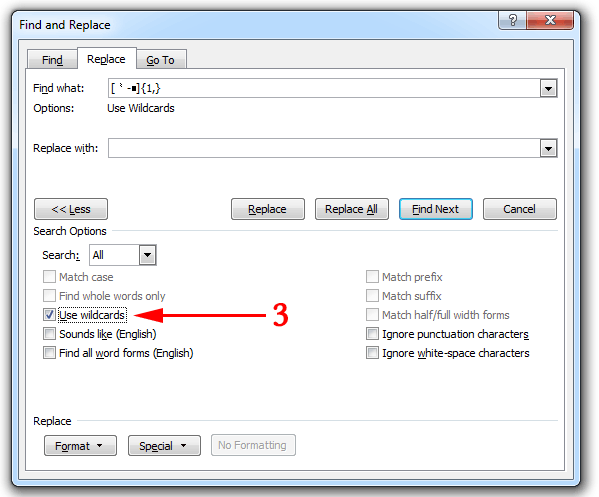
Look at the expanded Find and Replace box (the second image in this post; the one with a red arrow and the number 3).
In the bottom-left corner, just below “Replace” there is a drop-down box marked “Format”. Click on that and then select “Font”.
On the right side of the box that appears, there’s an entry form for “Size”. Enter “12” and then click “OK”.
Make sure when you’re doing this that you are applying this info to the “Find what” box (red arrow no. 1 above) or you’ll end up making all of your Chinese characters 12 point.
You don’t have to alter everything to a 14 point character style one by one. In the “Replace with” box, you can set the character style for everything that is found by using Format → Style.
Thanks for valuable information and I want to find Hebrew characters using string can you help me?
@Seenu: To find Hebrew letters and punctuation in a Microsoft Word document, try this:
[֑-״]{1,}
That’s likely to leave you with a lot of blank spaces, so this could probably use some tweaking. And I haven’t tried it on pointed text yet, though I think it will work. Regardless, it’ll get you started.
How would I do this for other languages, specifically Thai and Japanese? Thanks :-)
this is so useful, thank you. i used this method to delete tons of Chinese text interspersed in my English document.
what i found was that the specifically Chinese punctuation (such as ??) are deleted, but commas and question marks remain. is there any way i can configure the find and replace to delete the commas and question marks within the Chinese text as well?
@tc974, try
[⺀-■][\,\?][⺀-■]
(Be sure to have “use wildcards” turned on.)
That will eliminate regular (i.e., non-Chinese) commas and question marks when they are surrounded on both sides by Chinese characters. Then run the search given in the post at the top of this page to get rid of all the Chinese characters.
If that still leaves you with some question marks and commas at the end of phrases or paragraphs, you could go with
[⺀-■][\,\?]
hi Pinyin Info, your second suggestion to find [?-?][\,\?] worked beautifully. thank you!
Do you know if it’s possible to remove all English (or non-Chinese) words and numbers/symbols within a chunk of Chinese text? eg:
??2024?3?15?????help???(lpl@weaolc.com)???????1-3?????Mr Poole?????????VIP?????2/3???19?????????????$234.50???King & Co?????34%?????????Article 4.5???????????
Using your find and replace trick, what’s left is:
2024315help(lpl@weaolc.com)1-3Mr PooleVIP2/319$234.50King & Co34%Article 4.5
which is already good enough for me as i will be manually going through the document.
i could create a macro combining different find and replace actions,
eg [?-?][0-9]{1,}[?-?]. was wondering if you know of a shortcut?
To reverse the search (i.e., find everything except for Chinese characters), add an exclamation mark:
[!⺀-■]{1,}