
Some eight years ago UTF-8 (Unicode) became the most used encoding on Web pages. At the time, though, it was used on only about 26% of Web pages, so it had a plurality but not an absolute majority.
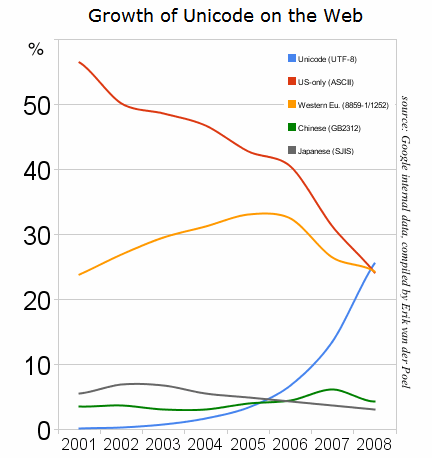
By the beginning of 2010 Unicode was rapidly approaching use on half of Web pages.
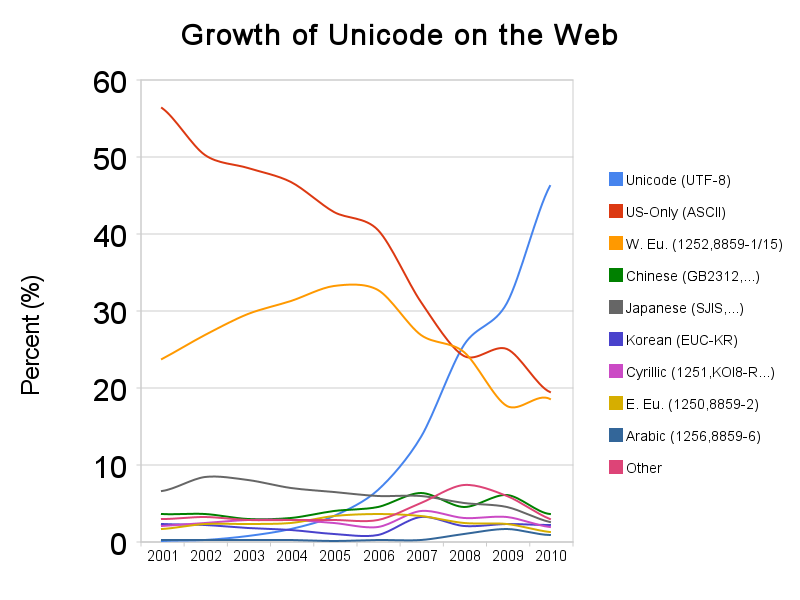
In 2012 the trends were holding up.
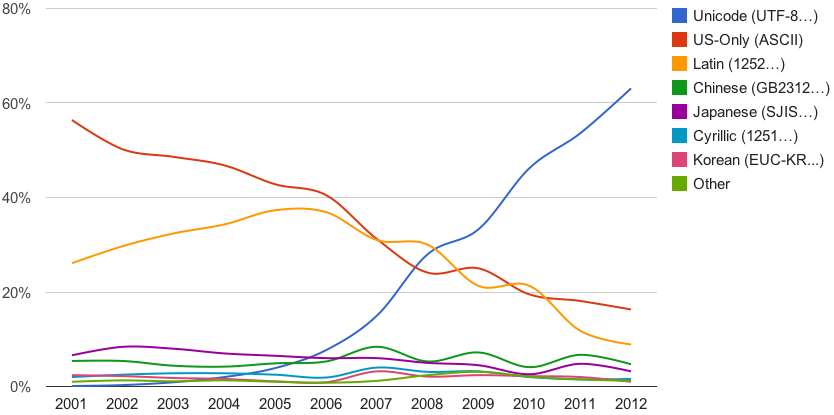
Note that the 2008 crossover point appears different in the latter two Google graphs, which is why I’m showing all three graphs rather than just the third.
A different source (with slightly different figures) provides us with a look at the situation up to the present, with UTF-8 now on 85% of Web pages. Expansion of UTF-8 is slowing somewhat. But that may be due largely to the continuing presence of older websites in non-Unicode encodings rather than lots of new sites going up in encodings other than UTF-8.

Here’s the same chart, but focusing on encodings (other than UTF-8) that use Chinese characters, so the percentages are relatively low.
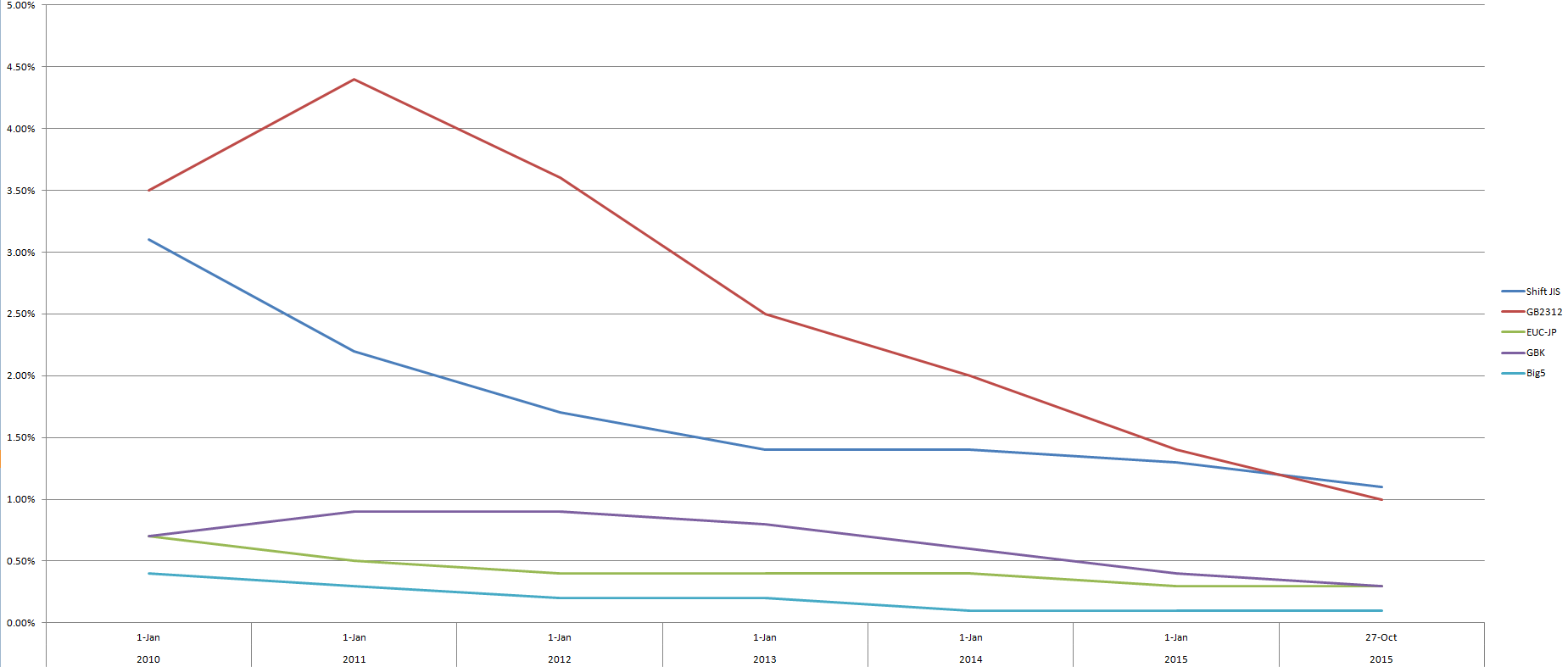
And here’s the same as the above, but with the results for individual languages combined.
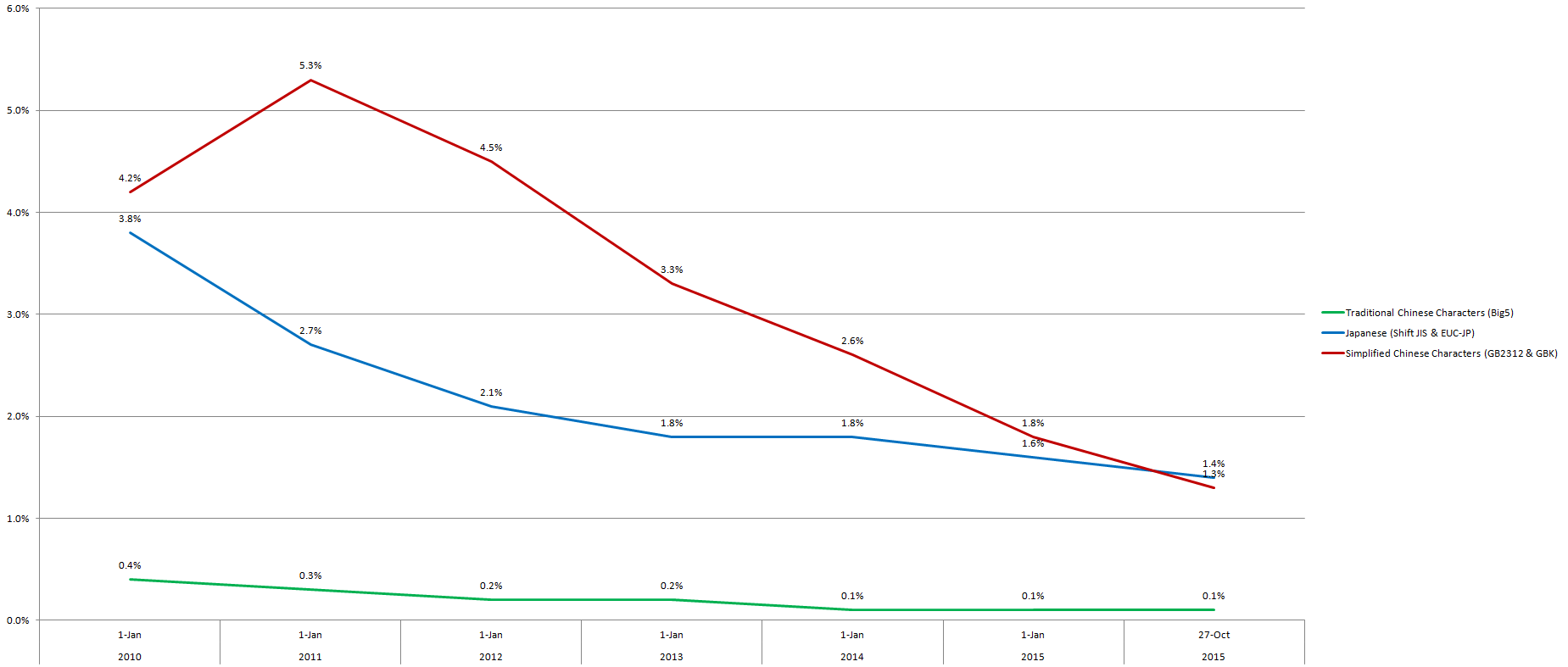
By the way, Pinyin.info has been in UTF-8 since the site began way back in 2001. The reason that Chinese characters and Pinyin with tone marks appear scrambled within Pinyin News is that a hack caused the WordPress database to be set to Swedish (latin1_swedish_ci), of all things. And I haven’t been able to get it fixed; so just for the time being I’ve given up trying. One of these days….
Sources:
- Unicode tops other encodings on Web pages: Google, May 7, 2008, Pinyin News
- Unicode nearing 50% of the web, January 28, 2010, Google Official Blog
- Unicode over 60 percent of the web, February 3, 2012, Google Official Blog
- Historical yearly trends in the usage of character encodings for websites, accessed October 27, 2015
Ah, wrong DB character encoding… Yes, I made that mistake too when I started with these things, this leads to “funny” effects, so I’m not sure if you will ever be able to fix this, having unicode characters in a latin1 DB, and perhaps you already know this, but just in case you don’t:
ALTER DATABASE databasename CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE tablename CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
I also found this oneliner (Fill in “dbname”.), if you can access MySQL through command line:
DB=”dbname”; ( echo ‘ALTER DATABASE `'”$DB”‘` CHARACTER SET utf8 COLLATE utf8_unicode_ci;’; mysql “$DB” -e “SHOW TABLES” –batch –skip-column-names | xargs -I{} echo ‘ALTER TABLE `'{}’` CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;’ ) | mysql “$DB”
This can’t go on. Can you email me a dump of your wp_posts table? I’ll see if I can do anything.
I always tell people to prefer PostgreSQL over MySQL, and the most important reason is the inane encoding settings of MySQL. Years ago when I last worked with that RDBMS, I remember I had to set encoding to UTF-8 in no less than *four* places: the database, the table, the connection, and somewhere else. Crazy.
I would be interested to know what are the most popular encodings in China by percentage wise thanks.