
Google is reporting that in December 2007 Unicode became the most frequently used encoding on Web pages.
Just last December there was an interesting milestone on the web. For the first time, we found that Unicode was the most frequent encoding found on web pages, overtaking both ASCII and Western European encodings—and by coincidence, within 10 days of one another. What’s more impressive than simply overtaking them is the speed with which this happened.
Here’s Google’s graph:
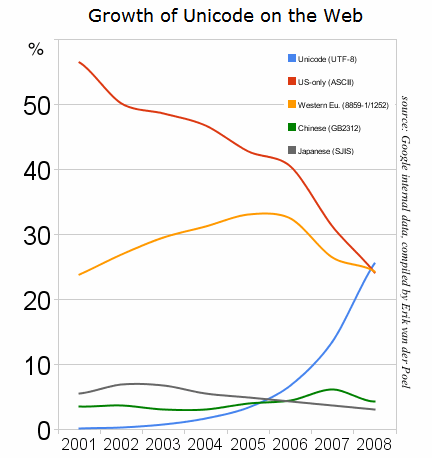
I wish Big5, the encoding most used for Web pages in traditional Chinese characters, had been included in the graph. And I suspect that it’s only within the past ten years — perhaps even within the timeframe of the graph — that more Web pages have been encoded in GB (used for so-called simplified Chinese characters) than Big5. (GB is shown on the graph in green.)
Of course, many (most?) Web pages don’t declare any character encoding. This is especially bad when they contain characters beyond the bounds of ASCII, since those characters will often end up rendered as garbage on systems different than that of the creator of the Web page.
So … should I have a post focusing on Unicode without again berating the Unicode Consortium for its continuing unscientific, egregious, and unforgivable use of ideographic? I don’t think so.
source: Moving to Unicode 5.1, Official Google Blog, May 5, 2008
Nice to have this confirmed. So in about three or four years, local IT companies (“We have always been using Big5!”) too may jump onto the Unicode train…
Unicode is not an encoding though, UTF-8 or UTF-16 is.
Well, the graph says it’s UTF-8…
Pingback: UTF-8 Unicode vs. other encodings over time | Pinyin News